1 Czym jest Cortex Code?
Cortex Code to asystent programistyczny oparty na AI, zintegrowany ze Snowsight — środowiskiem webowym Snowflake. Umożliwia generowanie kodu SQL, Python i Streamlit bezpośrednio z języka naturalnego, przyspieszając rozwój rozwiązań analitycznych.
Główne możliwości
- Generowanie kodu SQL — CREATE TABLE, INSERT, widoki, procedury, funkcje
- Cortex AI/ML — ML.CLASSIFICATION, ML.FORECAST, CORTEX.COMPLETE, CORTEX.SENTIMENT, Cortex Search
- Feature Store — Entity, FeatureView, get_features()
- Model Registry — log_model(), get_model(), wersjonowanie
- Streamlit — Generowanie interaktywnych dashboardów
- Tasks & Pipelines — Automatyzacja i orkiestracja
Ważne: Cortex Code generuje kod, który jest wykonywany na Twoim koncie Snowflake. Wszystko pozostaje w Twoim środowisku — bez zewnętrznych zależności, bez wysyłania danych na zewnątrz.
2 Wymagania wstępne
Przed rozpoczęciem upewnij się, że masz skonfigurowane następujące elementy:
Konto Snowflake
Ważne: Poprosi swojego przedstawiciela Snowflake o utworzenie niezbędnych kont dla Twojego zespołu. W ten sposób zapewniamy obsługę wszystkich funkcji Cortex Code i Cortex AI: ML.CLASSIFICATION, ML.FORECAST, CORTEX.COMPLETE, CORTEX.SENTIMENT, Cortex Search i Feature Store.
Dostęp do Cortex Code w Snowsight
Po zalogowaniu się na konto, po prawej stronie ekranu pojawi się panel asystenta Cortex Code. To Twój partner programistyczny AI do uruchamiania wszystkich promptów z tego katalogu:
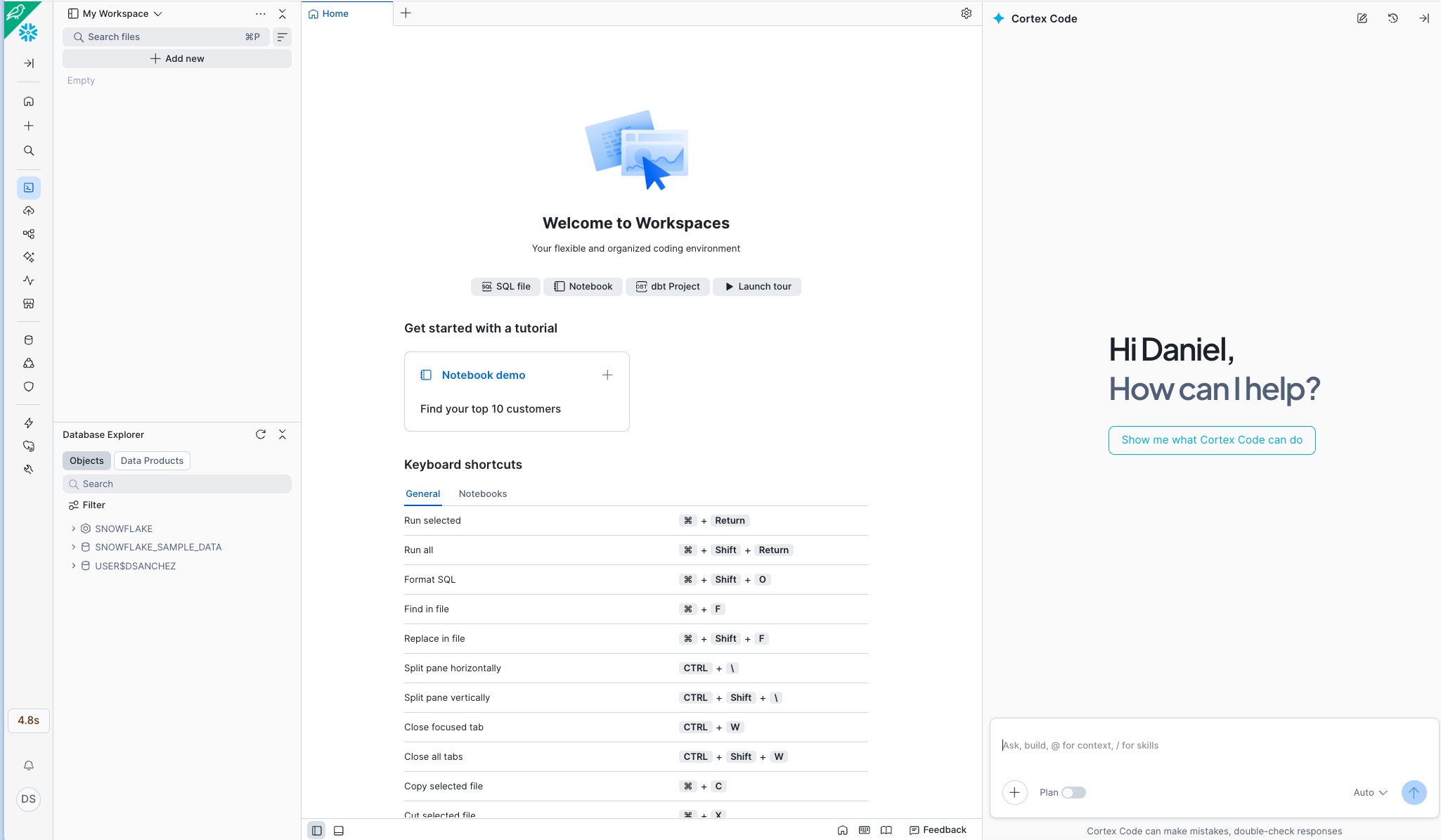
Gotowe: Jeśli widzisz panel Cortex Code z komunikatem «How can I help?» po prawej stronie, możesz zacząć kopiować i wklejać prompty z dowolnego przypadku użycia.
Konto i uprawnienia
- Konto Snowflake z dostępem do Snowsight
- Rola z uprawnieniami CREATE DATABASE, CREATE SCHEMA, CREATE TABLE
- Aktywny warehouse (zalecany: rozmiar S do rozwoju, M do produkcji)
- Cortex Code włączony na koncie (dostępny we wszystkich edycjach)
Dla zaawansowanych funkcji
- Cortex AI/ML: Wymaga regionu obsługującego Cortex Functions (AWS us-west-2, us-east-1, eu-west-1 itp.)
- Feature Store: Dostępny pakiet
snowflake-ml-python - Model Registry: Uprawnienia do tworzenia modeli w schemacie
- Streamlit: Uprawnienie CREATE STREAMLIT w schemacie
Uwaga dotycząca regionów: Niektóre funkcje Cortex AI (takie jak ML.CLASSIFICATION czy CORTEX.COMPLETE) wymagają określonych regionów. Sprawdź dokumentację dostępności, aby zweryfikować swój region.
3 Otwarcie Cortex Code w Snowsight
Cortex Code jest zintegrowany z różnymi elementami Snowsight. Oto sposoby dostępu:
Opcja A — Z poziomu Workspaces
- Wejdź do Snowsight → Projects → Workspaces
- Utwórz lub otwórz istniejący workspace
- Kliknij ikonę Cortex (✨) na prawym pasku bocznym lub użyj skrótu Cmd+Shift+Space (Mac) / Ctrl+Shift+Space (Windows)
- Panel Cortex Code otworzy się po prawej stronie edytora
Wskazówka: Panel Cortex Code zachowuje kontekst Twojego workspace. Jeśli masz tabele wymienione w edytorze, Cortex Code wykorzysta je jako kontekst do generowania bardziej precyzyjnego kodu.
4 Dodanie Skill Best-Practices do Cortex Code
Aby poprawić wydajność i zmniejszyć koszty generowanego kodu, możesz dodać skill best-practices do Cortex Code. Po załadowaniu będzie dostępny przed każdym promptem i pomoże asystentowi generować bardziej wydajny i zoptymalizowany kod dla Snowflake.
4.1 — Pobranie skill
Pobierz skompresowany plik ze skill best-practices i zapisz go na swoim komputerze:
4.2 — Rozpakowanie lokalne
Rozpakuj pobrany plik na swoim komputerze. Otrzymasz folder o nazwie best-practices z plikami skill gotowymi do przesłania.
Wskazówka: Rozpakuj w łatwo dostępnym miejscu (np. na Pulpicie lub w folderze Pobrane), ponieważ w następnym kroku będziesz musiał go wybrać z poziomu Snowsight.
4.3 — Przesłanie skill do Cortex Code w Snowsight
W Snowsight, w panelu Cortex Code, kliknij przycisk +, wybierz opcję «Upload Skill Folder(s)» i wskaż folder best-practices, który właśnie rozpakowałeś lokalnie:
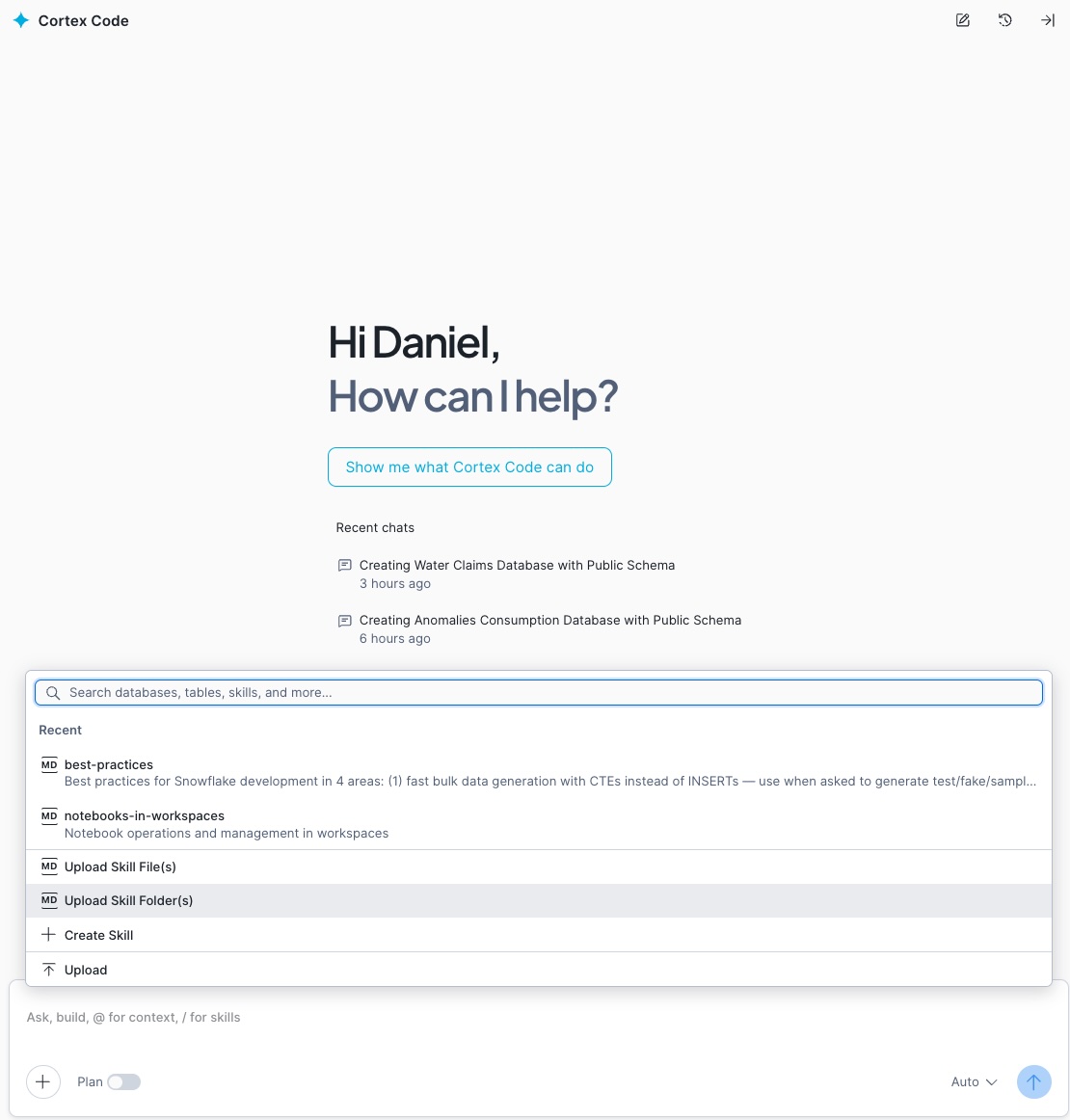
Uwaga: Przycisk + znajduje się w górnej części panelu Cortex Code, obok selektora kontekstu. Po kliknięciu pojawi się menu — wybierz «Upload Skill Folder(s)» i przejdź do miejsca, w którym rozpakowałeś skill.
4.4 — Użycie skill przed każdym promptem
Po przesłaniu skill będzie dostępny w Twojej sesji Cortex Code. Wpisz polecenie /best-practices przed każdym promptem, aby go aktywować i uzyskać bardziej wydajny kod:
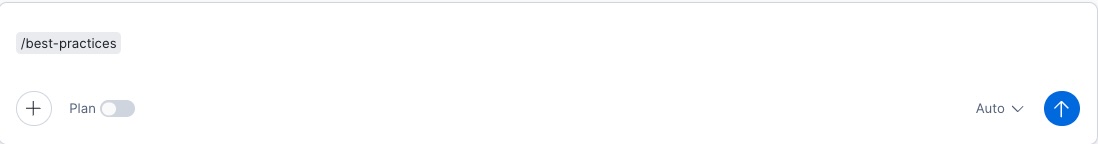
Gotowe: Po aktywacji skill Cortex Code automatycznie zastosuje dobre praktyki Snowflake we wszystkich generowanych kodach: efektywne wykorzystanie warehouseów, clustering keys, optymalizacja zapytań i redukcja kosztów kredytów.
5 Przepływ pracy z promptami
Każdy przypadek użycia w tym katalogu zawiera od 8 do 11 sekwencyjnych promptów. Zalecany przepływ pracy:
przypadku użycia
przewodnik
Cortex Code
każdy prompt
uruchom
Struktura każdego przypadku użycia
Po kliknięciu «Zobacz prompty» na karcie dowolnego przypadku użycia zobaczysz:
- Krok 1 — Konfiguracja środowiska: Tworzenie bazy danych, schematu i warehouse. Zawsze jest to pierwszy prompt.
- Kroki 2-4 — Tworzenie danych: Generowanie tabel z syntetycznymi danymi reprezentatywnymi dla danej dziedziny.
- Kroki 5-7 — Analiza i modelowanie: Features, modele ML, funkcje Cortex AI, Feature Store lub Model Registry.
- Kroki 8-9 — Dashboard: Kod Streamlit do interaktywnej wizualizacji.
- Ostatni krok — Pipeline: Tasks do automatyzacji i ciągłego działania.
Sekwencyjność: Prompty są zaprojektowane do wykonywania w kolejności. Każdy krok zależy od obiektów utworzonych w poprzednich krokach. Nie pomijaj kroków.
6 Wykonanie przypadku użycia krok po kroku
Zobaczmy cały proces na praktycznym przykładzie:
6.1 — Wybór branży i przypadku użycia
- Przejdź do katalogu branż
- Wybierz branżę (na przykład Bankowość)
- Przeglądaj karty lub użyj wyszukiwarki, aby znaleźć przypadek użycia
- Przeczytaj sekcję «Problem», aby zrozumieć wyzwanie biznesowe
6.2 — Przeczytaj przewodnik
- Kliknij «Zobacz przewodnik»
- Przeczytaj sekcje: Kontekst, Fokus, Wyzwanie, Cele, Funkcjonalności, Dane, Stratyfikacja i Jak używać
- To da Ci ramy koncepcyjne przed generowaniem kodu
6.3 — Uruchomienie promptów
- Kliknij «Zobacz prompty»
- W Snowsight otwórz workspace i aktywuj Cortex Code
- Dla każdego kroku:
- Kliknij «Kopiuj» przy promptcie
- Wklej go do panelu Cortex Code
- Cortex Code wygeneruje odpowiedni kod SQL/Python
- Sprawdź go przed uruchomieniem (patrz sekcja 7)
- Kliknij «Run» lub «Apply»
- Zweryfikuj poprawność wykonania
- Przejdź do następnego promptu
Oczekiwany rezultat: Po wykonaniu wszystkich kroków będziesz mieć: bazę danych z tabelami danych syntetycznych, wytrenowane modele ML, skonfigurowane funkcje Cortex AI oraz działający dashboard Streamlit.
7 Przegląd i walidacja wygenerowanego kodu
Cortex Code generuje kod wysokiej jakości, ale zawsze należy go sprawdzić przed uruchomieniem. Kluczowe punkty:
Lista kontrolna przeglądu
- Nazwy obiektów: Sprawdź, czy baza danych, schemat i warehouse odpowiadają Twojemu środowisku
- Rozmiar warehouse: Dostosuj rozmiar do obciążenia (S do rozwoju, M-L do produkcji)
- Wolumen danych syntetycznych: Prompty sugerują reprezentatywne wolumeny; dostosuj je według potrzeb
- Modele LLM: Sprawdź, czy dany model (np.
llama3.1-70b,mistral-large2) jest dostępny w Twoim regionie - Funkcje ML: Potwierdź, że ML.CLASSIFICATION, ML.FORECAST są dostępne
- Uprawnienia: Twoja rola musi posiadać wymagane granty na obiektach
Dostosowanie do danych rzeczywistych
Prompty generują dane syntetyczne w celach demonstracyjnych. Aby przenieść do produkcji:
- Zastąp syntetyczne
CREATE TABLE ... INSERTinstrukcjamiCREATE VIEWlubSELECTna Twoich rzeczywistych tabelach - Dostosuj nazwy kolumn do Twojego modelu danych
- Zmodyfikuj progi i parametry biznesowe
- Zachowaj strukturę features, modeli i dashboardów
Dane syntetyczne: Wygenerowane dane są fikcyjne i reprezentatywne. Nie należy ich używać w rzeczywistych raportach biznesowych. Służą do walidacji pipeline’u end-to-end przed podłączeniem danych rzeczywistych.
8 Wdrożenie dashboardów Streamlit
Prawie wszystkie przypadki użycia zawierają prompt do wygenerowania dashboardu Streamlit. Oto jak go wdrożyć:
8.1 — Wygenerowanie aplikacji Streamlit
- Uruchom prompt «Dashboard» (zwykle przedostatni krok)
- Cortex Code wygeneruje kod Python ze Streamlit
- Wejdź do Snowsight → Projects → Streamlit
8.3 — Weryfikacja i udostępnianie
- Sprawdź, czy wszystkie wykresy i tabele ładują się poprawnie
- Jeśli występują błędy, zweryfikuj, czy tabele i widoki istnieją (zostały utworzone w poprzednich krokach)
- Udostępnij aplikację innym użytkownikom za pomocą «Share»
9 Automatyzacja za pomocą Tasks i Pipelines
Ostatni prompt każdego przypadku użycia tworzy Tasks Snowflake w celu automatyzacji pipeline’u:
Co jest automatyzowane
- Pobieranie danych: Okresowe ładowanie ze źródeł (dzienne, tygodniowe)
- Aktualizacja features: Przeliczanie wskaźników i metryk
- Scoring ML: Uruchamianie modeli na nowych danych
- Alerty: Powiadomienia po przekroczeniu progów
- Ponowne trenowanie: Okresowa aktualizacja modeli
Typowa struktura Tasks
DAG Tasks: Zaawansowane przypadki użycia tworzą DAG-i (Directed Acyclic Graphs), w których jedne Tasks zależą od innych. Cortex Code automatycznie generuje zależności za pomocą AFTER.
10 Sprawdzenie zużytych kosztów
Po uruchomieniu jednego lub kilku przypadków użycia użyj tego promptu w Cortex Code, aby uzyskać zbiorczy raport wszystkich kredytów i tokenów zużytych w bieżącym dniu: warehouse, funkcje Cortex AI, modele ML i Cortex Code w Snowsight.
Prompt — Podsumowanie kosztów dnia
Skopiuj i wklej ten prompt bezpośrednio do Cortex Code (pamiętaj o aktywacji /best-practices wcześniej):
Uwaga: Dane z ACCOUNT_USAGE mają opóźnienie do 45 minut. Jeśli właśnie uruchomiłeś przypadek użycia i dane nie są widoczne, odczekaj kilka minut i uruchom zapytanie ponownie.
Alternatywa: Jeśli CORTEX_FUNCTIONS_USAGE_HISTORY nie jest dostępny na Twoim koncie, Cortex Code automatycznie zastąpi tę sekcję widokiem METERING_DAILY_HISTORY z service_type = 'AI_SERVICES'.
11 Wskazówki i dobre praktyki
Rozwój
- Zawsze używaj
/best-practicesprzed każdym promptem — Aktywuj skill, aby Cortex Code od pierwszego kroku generował kod zoptymalizowany pod kątem wydajności i kosztów - Wykonuj prompt po promptcie — Nie próbuj uruchamiać wszystkich promptów naraz; każdy krok weryfikuje poprzedni
- Nazywaj obiekty konsekwentnie — Prompty sugerują opisowe nazwy, takie jak
BANKING_FRAUD_DB - Zapisuj worksheet — Każdy przypadek użycia generuje sporo kodu; zapisuj często
Cortex Code
- Bądź precyzyjny w promptach — Prompty w katalogu są już szczegółowe, ale możesz dodać kontekst swojego biznesu
- Iteruj nad kodem — Jeśli wygenerowany kod nie jest dokładnie tym, czego potrzebujesz, poproś Cortex Code o dostosowanie
- Wykorzystuj kontekst workspace — Jeśli masz już tabele w edytorze, Cortex Code automatycznie się do nich odwoła
- Łącz prompty w razie potrzeby — Dla zaawansowanych użytkowników można połączyć 2-3 kroki w jeden dłuższy prompt
Produkcja
- Zastąp dane syntetyczne rzeczywistymi — Pipeline działa tak samo, wystarczy zmienić źródło danych
- Skonfiguruj Resource Monitors — Kontroluj zużycie kredytów warehouse
- Sprawdź uprawnienia — Używaj osobnych ról dla każdego projektu (data_scientist, analyst itp.)
- Monitoruj Tasks — Przeglądaj historię wykonania w Activity → Task History
- Wersjonuj modele — Przypadki z Model Registry już zawierają wersjonowanie; używaj go do testów A/B
12 Często zadawane pytania
best-practices.zip), rozpakowanie go na komputerze i przesłanie folderu do Cortex Code za pomocą przycisku + w Snowsight. Po przesłaniu będzie dostępny pod poleceniem /best-practices i nie będziesz musiał powtarzać tego procesu.